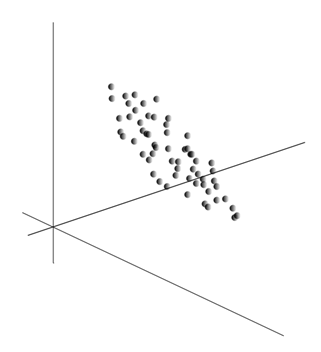
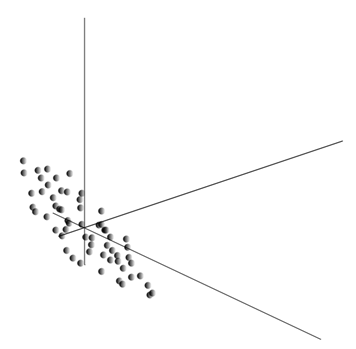
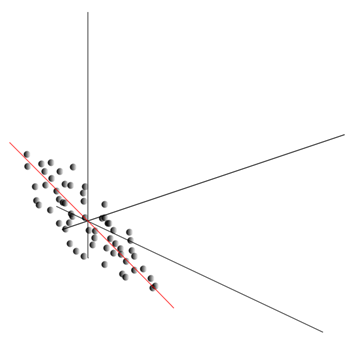
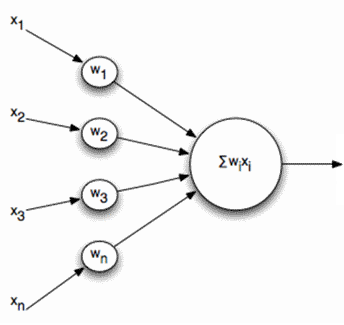
Мы показали, как фильтр Хебба выделяет первую главную компоненту. Оказывается, с помощью нейронных сетей можно с легкостью получить не только первую, но и все остальные компоненты. Это можно сделать, например, следующим способом. Предположим, что у нас \(m\) входных признаков. Возьмем \(l\) линейных нейронов, где \(l\)<\(m\).
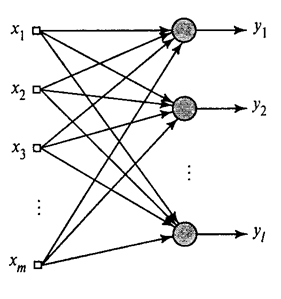
Обобщенный алгоритм Хебба (Хайкин, 2006)
Будем обучать первый нейрон как фильтр Хебба, чтобы он выделил первую главную компоненту. А вот каждый последующий нейрон будем обучать на сигнале, из которого исключим влияние всех предыдущих компонент.
Активность нейронов на шаге n определяется как
\[y_{j}(n)=\sum_{i=1}^{m}\omega _{ji}(n)x_{i}(n)\]
А поправка к синоптическим весам как
\[\Delta \omega _{ji}(n)=\eta \left(y_{j}(n)x_{n}-y_{j}(n)\sum_{k=1}^{j}\omega _{ki}(n)y_{k}(n)\right )\]
где \(i\) от 1 до \(m\), а \(j\) от 1 до \(l\).
Для всех нейронов это выглядит как обучение, аналогичное фильтру Хебба. С той лишь разницей, что каждый последующий нейрон видит не весь сигнал, а только то, что «не увидели» предыдущие нейроны. Этот принцип называется повторным оцениванием. Мы фактически по ограниченному набору компонент производим восстановление исходного сигнала и заставляем следующий нейрон видеть только остаток, разницу между исходным сигналом и восстановленным. Этот алгоритм называется обобщенным алгоритмом Хебба.
В обобщенном алгоритме Хебба не совсем хорошо то, что он носит слишком «вычислительный» характер. Нейроны должны быть упорядочены, и обсчет их деятельности должен осуществляться строго последовательно. Это не очень сочетается с принципами работы коры мозга, где каждый нейрон хотя и взаимодействует с остальными, но работает автономно, и где нет ярко выраженного «центрального процессора», который бы определял общую последовательность событий. Из таких соображений несколько привлекательнее выглядят алгоритмы, называемые алгоритмами декорреляции.
Представим, что у нас есть два слоя нейронов Z1 и Z2. Активность нейронов первого слоя образует некую картину, которая проецируется по аксонам на следующий слой.
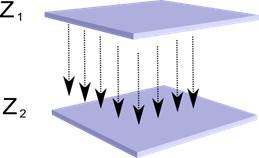
Проекция одного слоя на другой
Теперь представим, что каждый нейрон второго слоя имеет синаптические связи со всеми аксонами, приходящими с первого слоя, если они попадают в границы определенной окрестности этого нейрона (рисунок ниже). Аксоны, попадающие в такую область, образуют рецептивное поле нейрона. Рецептивное поле нейрона – это тот фрагмент общей активности, который доступен ему для наблюдения. Всего остального для этого нейрона просто не существует.
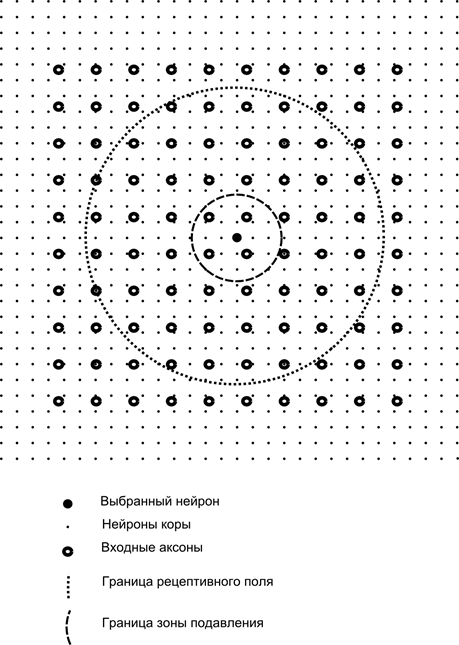
Помимо рецептивного поля нейрона введем область несколько меньшего размера, которую назовем зоной подавления. Соединим каждый нейрон со своими соседями, попадающими в эту зону. Такие связи называются боковыми или, следуя принятой в биологии терминологии, латеральными. Сделаем латеральные связи тормозящими, то есть понижающими активность нейронов. Логика их работы – активный нейрон тормозит активность всех тех нейронов, что попадают в его зону торможения.
Возбуждающие и тормозящие связи могут быть распределены строго со всеми аксонами или нейронами в границах соответствующих областей, а могут быть заданы случайно, например, с плотным заполнением некого центра и экспоненциальным убыванием плотности связей по мере удаления от него. Сплошное заполнение проще для моделирования, случайное распределение более анатомично с точки зрения организации связей в реальной коре.
Функцию активности нейрона можно записать:
\[y_{j}=max(O,\sum_{i\in R_{j}}x_{i}\omega _{ji}+\sum_{k\in L_{j}}y_{k}a_{jk})\]
Где – \(y_{j}\) итоговая активность, – \(R_{j}\)множество аксонов, попадающих в рецептивную область выбранного нейрона, \(L_{j}\)– множество нейронов, в зону подавления которых попадает выбранный нейрон, \(a_{jk}\)– сила соответствующего латерального торможения, принимающая отрицательные значения.
Такая функция активности является рекурсивной, так как активность нейронов оказывается зависимой друг от друга. Это приводит к тому, что практический расчет производится итерационно.
Обучение синаптических весов делается аналогично фильтру Хебба:
\[\omega _{ji}(n+1)=\omega _{ji}(n)+\eta y_{j}(n)(x_{i}(n)-y_{j}(n)\omega _{ji}(n))\]
Латеральные веса обучаются по анти-Хеббовскому правилу, увеличивая торможение между «похожими» нейронами:
\[a_{ji}(n+1)=a_{ji}(n)-\eta y_{j}(n)(y_{i}(n)-y_{j}(n)a_{ji}(n))\]
Суть этой конструкции в том, что Хеббовское обучение должно привести к выделению на весах нейрона значений, соответствующих первому главному фактору, характерному для подаваемых данных. Но нейрон способен обучаться в сторону какого-либо фактора, только если он активен. Когда нейрон начинает выделять фактор и, соответственно, реагировать на него, он начинает блокировать активность нейронов, попадающих в его зону подавления. Если на активацию претендует несколько нейронов, то взаимная конкуренция приводит к тому, что побеждает сильнейший нейрон, угнетая при этом все остальные. Другим нейронам не остается ничего другого, кроме как обучаться в те моменты, когда рядом нет соседей с высокой активностью. Таким образом, происходит декорреляция, то есть каждый нейрон в пределах области, размер которой определяется размером зоны подавления, начинает выделять свой фактор, ортогональный всем остальным. Этот алгоритм называется алгоритмом адаптивного извлечения главных компонент (APEX) (Kung S. , Diamantaras K.I., 1990).
Идея латерального торможения близка по духу хорошо известному по разным моделям принципу «победитель забирает все», который также позволяет осуществить декорреляцию той области, в которой ищется победитель. Этот принцип используется, например, в неокогнитроне Фукушимы, самоорганизующихся картах Коханена, также этот принцип применяется в обучении широко известной иерархической темпоральной памяти Джеффа Хокинса.
Определить победителя можно простым сравнением активности нейронов. Но такой перебор, легко реализуемый на компьютере, несколько не соответствует аналогиям с реальной корой. Но если задаться целью сделать все на уровне взаимодействия нейронов без привлечения внешних алгоритмов, то того же результата можно добиться, если кроме латерального торможения соседей нейрон будет иметь положительную обратную связь, довозбуждающую его. Такой прием для поиска победителя используется, например, в сетях адаптивного резонанса Гроссберга.
Если идеология нейронной сети это допускает, то использовать правило «победитель забирает все» очень удобно, так как искать максимум активности значительно проще, чем итерационно обсчитывать активности с учетом взаимного торможения.